20.7 Rattle Build Tree
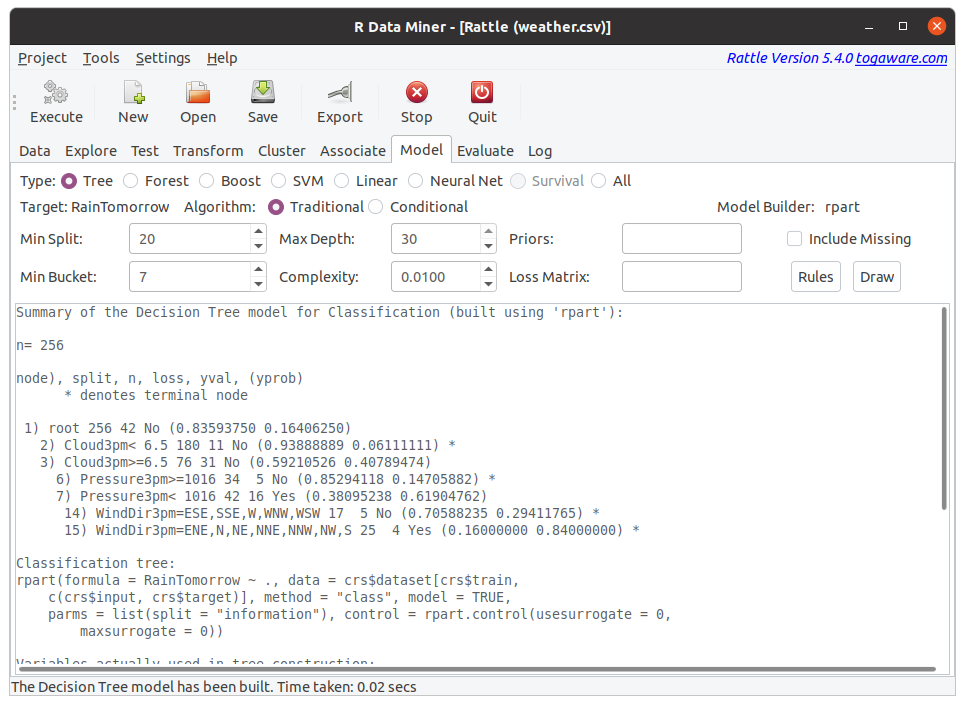
We can simply click the Execute button to build our first decision tree, using all of the default settings. Once finished, as in the figure above, the time taken to build the tree is reported in the status bar at the bottom of the window. A summary of the tree is presented in the text view panel. A classification model is built using rpart::rpart().
The number of observations from which the model was built is reported. This is 70% of the observations available in the dataset, representing the training dataset. We again note that the weather dataset is quite a tiny dataset in the context of data mining, but suitable for our purposes here.
The actual decision tree is then presented in its textual form.
Your donation will support ongoing availability and give you access to the PDF version of this book. Desktop Survival Guides include Data Science, GNU/Linux, and MLHub. Books available on Amazon include Data Mining with Rattle and Essentials of Data Science. Popular open source software includes rattle, wajig, and mlhub. Hosted by Togaware, a pioneer of free and open source software since 1984. Copyright © 1995-2022 Graham.Williams@togaware.com Creative Commons Attribution-ShareAlike 4.0
