14.13 Biased Estimate from the Training Dataset
We noted above that evaluating a model on the training
dataset on which the model was built will result in overly optimistic
performance outcomes. We can compare the performance of the
randomForest::randomForest() model on the te dataset
presented above with that on the training dataset. As
expected the performance on the training dataset is wildly
optimistic. In fact it is common for the
randomForest (Breiman et al. 2024) model to predict perfectly over the
training dataset as we see from the confusion matrix.
## Predicted
## Actual No Yes
## No 76 3
## Yes 14 8Similarly Figure @ref(fig:memplate:rf_riskchart_tr) illustrates the
problem of evaluating a model based on the training
dataset. Again we see perfect performance when we evaluate the model
on the training dataset. The performance line (the Recall
which is plotted as the green line) follows the best achievable which
is the grey line.
pr_tr <- predict(model, newdata=ds[tr, vars], type="prob")[,2]
riskchart(pr_tr, actual_tr, risk_tr, title.size=14) +
labs(title="Risk Chart - " %s+% mtype %s+% " - Training Dataset")## Warning in ggplot2::guide_legend(keywidth = 3, labels = 1:3, title = "Legend"): Arguments in `...` must be used.
## ✖ Problematic argument:
## • labels = 1:3
## ℹ Did you misspell an argument name?
## Arguments in `...` must be used.
## ✖ Problematic argument:
## • labels = 1:3
## ℹ Did you misspell an argument name?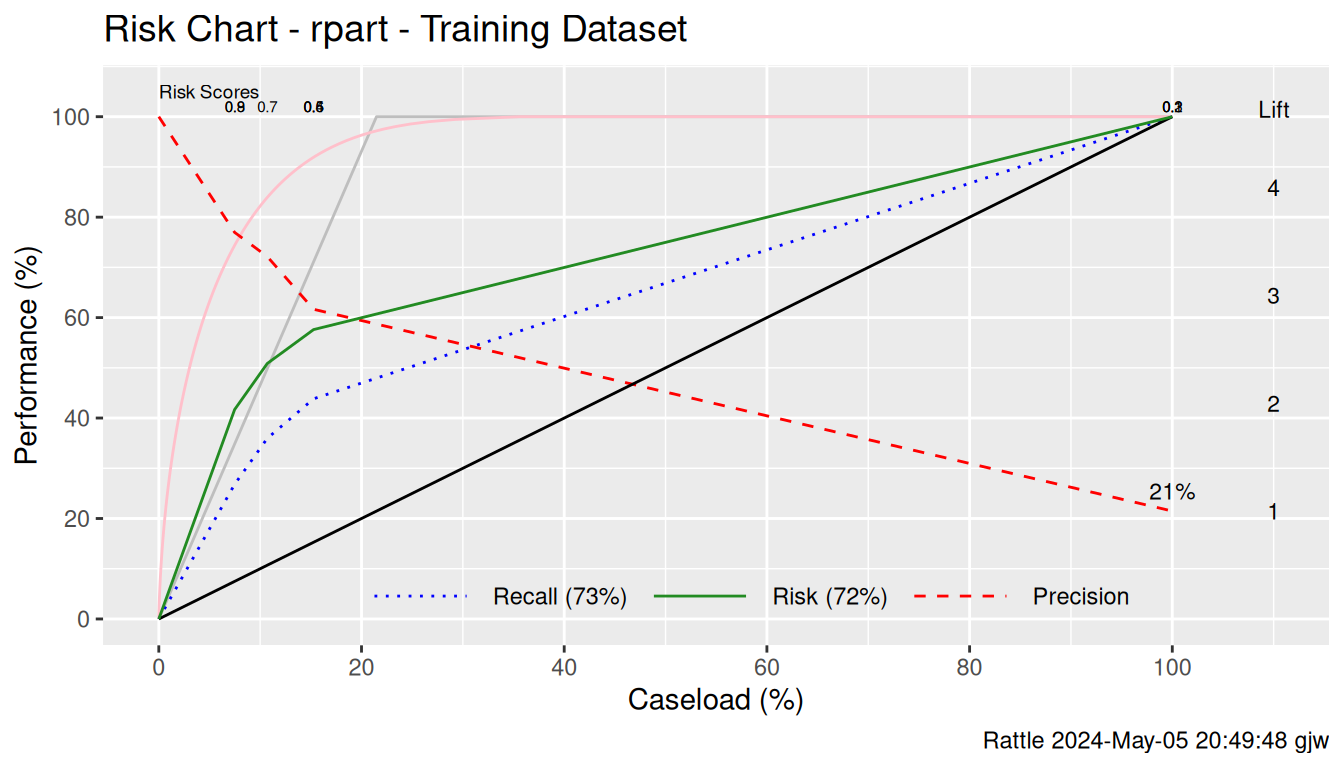
References
Your donation will support ongoing availability and give you access to the PDF version of this book. Desktop Survival Guides include Data Science, GNU/Linux, and MLHub. Books available on Amazon include Data Mining with Rattle and Essentials of Data Science. Popular open source software includes rattle, wajig, and mlhub. Hosted by Togaware, a pioneer of free and open source software since 1984. Copyright © 1995-2022 Graham.Williams@togaware.com Creative Commons Attribution-ShareAlike 4.0
