
by Graham Williams
|
|
Data Science Desktop Survival Guide
by Graham Williams |
|
|||
Differential Privacy | 




|
Differential privacy developed in 2006 by Cynthia Dwork is now widely used across industry so that data can be shared with limited impact on privacy.
The concept is to share aggregate data without disclosing individual data, by statistically perturbing the data in such a way so as not to lose the anlaytical value of the data.
Consider if we shared observations of 100 people (e.g., outcomes of a medical test), and in aggregate note that 70 test positive and 30 test negative. Later we might find the test results for the other 99 patients. Then we can determine the outcome for the remaining patient based on the supplied aggregate data! This is referred to as a differential attack and is difficult to protect against as we do not in general know how much other data may become available.
Differential privacy adds random noise to the aggregated data so instead of 70 patients testing positive it might be 68 or 69 or 71 or 72 that are reported as positive. It is roughly 70% and so any analysis remains generally valid whilst not being precise. The random perturbation introduced provides a level of privacy. Even knowing the test outcomes for 99 patients, the final patients test outcome can not be ascertained.
Mathematically it can be determined for a dataset how much noise is enough for specific requirements of differential privacy.
Applications include location-based services, social networks, and recommendation systems, with a body of research focused on differential privacy in graphs.
Machine learning in this context will train on aggregated dataset and
obfuscated using differential privacy noise. Or trained on
centrally-located data obfuscated using LDP noise. Performance
degradation is
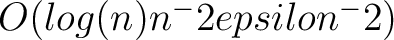 and
and
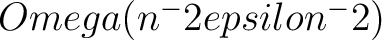 (Bassil et al 2014) Epsilon is the privacy budget. Larger datasets can
deliver better privacy. Distributed ML with DP asks each contributor
to add DP noice to the gradient cacluations.
(Bassil et al 2014) Epsilon is the privacy budget. Larger datasets can
deliver better privacy. Distributed ML with DP asks each contributor
to add DP noice to the gradient cacluations.